A Survey of Personalized Large Language Models: Progress and Future Directions
—— A systematic taxonomy of personalized LLMs across prompting, adaptation, alignment, evaluation, and future directions.
Why personalization?
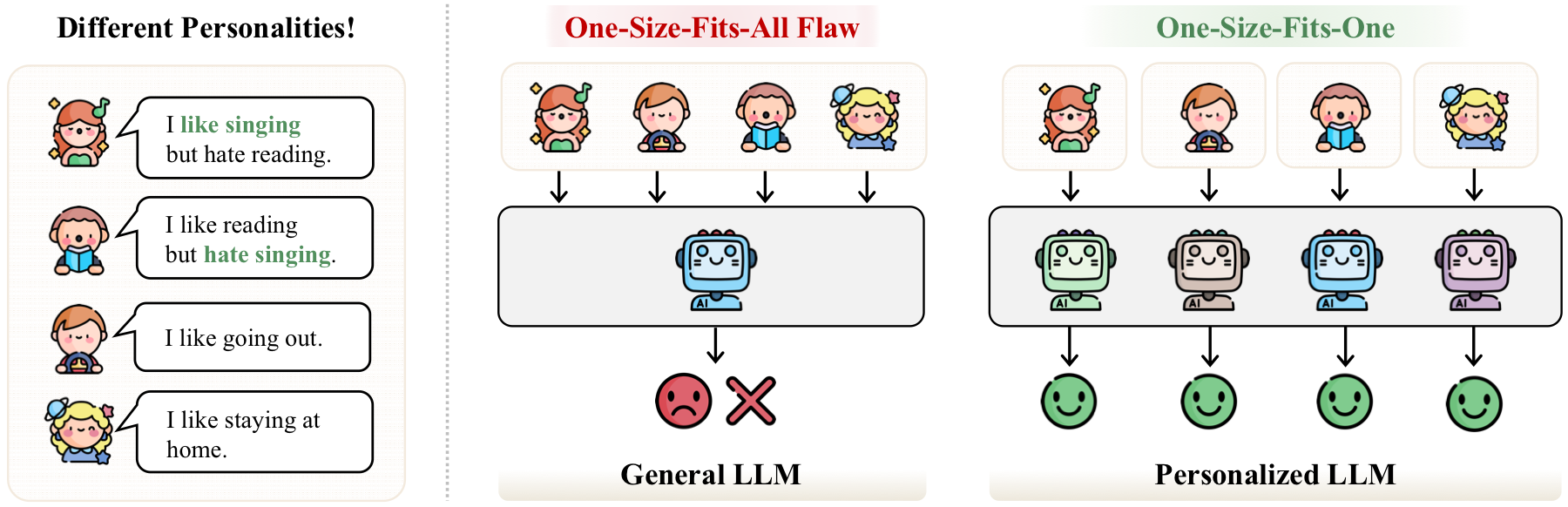
General LLMs know a lot, but they do not know you.
A general-purpose LLM is usually optimized for population-level usefulness. That is powerful, but it also creates a one-size-fits-all behavior: the same query tends to receive a generic answer even when users differ in taste, history, language style, goals, and constraints. Personalized Large Language Models (PLLMs) aim to move from this one-size-fits-all setting toward one-size-fits-one systems.
What This Survey Organizes
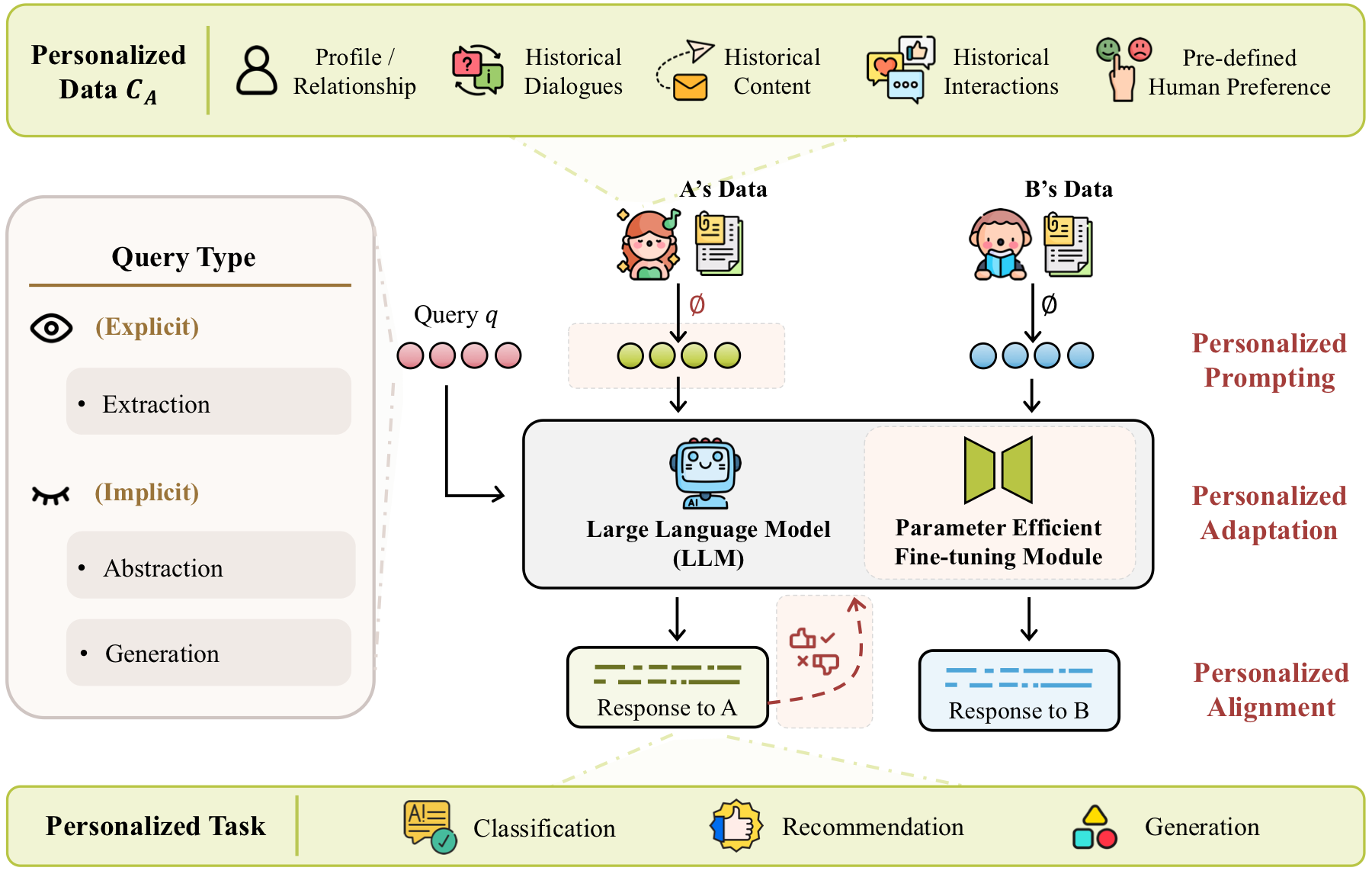
Personalized Data
Profiles, relationships, historical dialogues, historical content, interactions, and preference signals.
Technical Levels
Input-level prompting, model-level adaptation, and objective-level alignment.
Evaluation Landscape
Benchmarks across extraction, abstraction, generalization, classification, generation, and recommendation.
The taxonomy
Three places to inject personalization
The paper frames PLLM methods around the personalization operation: how user-specific data is turned into behavior that changes a model's response. The key organizing idea is simple and useful. Personalization can happen before the model sees the input, inside the model through adapted parameters or modules, or in the learning objective that defines which responses are preferred.
Input Level: Prompting
Keep the base LLM fixed. Build prompts, retrieved memories, soft prompts, or contrastive steering signals from user data.
Model Level: Adaptation
Change model behavior through PEFT modules, user embeddings, LoRA variants, MoE-style routing, or per-user adapters.
Objective Level: Alignment
Optimize or decode with user-specific preferences, reward models, model merging, ensembles, or test-time feedback.
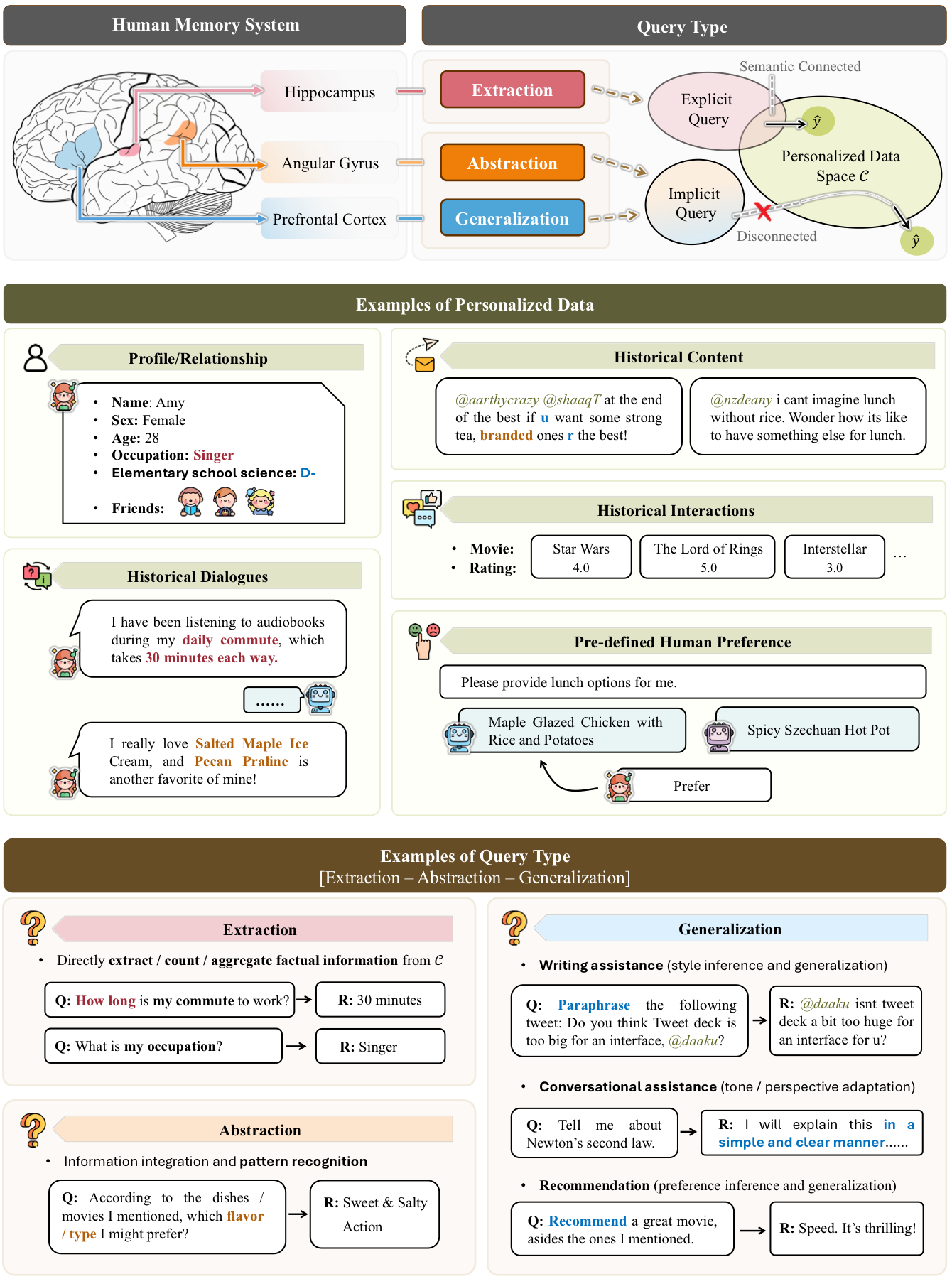
What does a personalized query ask?
Extraction, abstraction, and generalization require different memory behavior
Not every personalized query is equally hard. Some questions ask the system to extract an explicit fact from a user's history. Others require abstraction, where the model must summarize or infer higher-level preferences. The hardest cases often require generalization: the model must use personal evidence plus external knowledge to produce a response that fits the user but is not directly stated in the history.
Path 1
Personalized Prompting: efficient, flexible, but bounded by context
Prompting-based methods put personalization around the frozen LLM. They are attractive because they are cheap to deploy, work well with black-box models, and can update memories without retraining the generator. The survey separates this family into four subtypes: profile-augmented prompting, retrieval-augmented prompting, soft-fused prompting, and contrastive prompting.
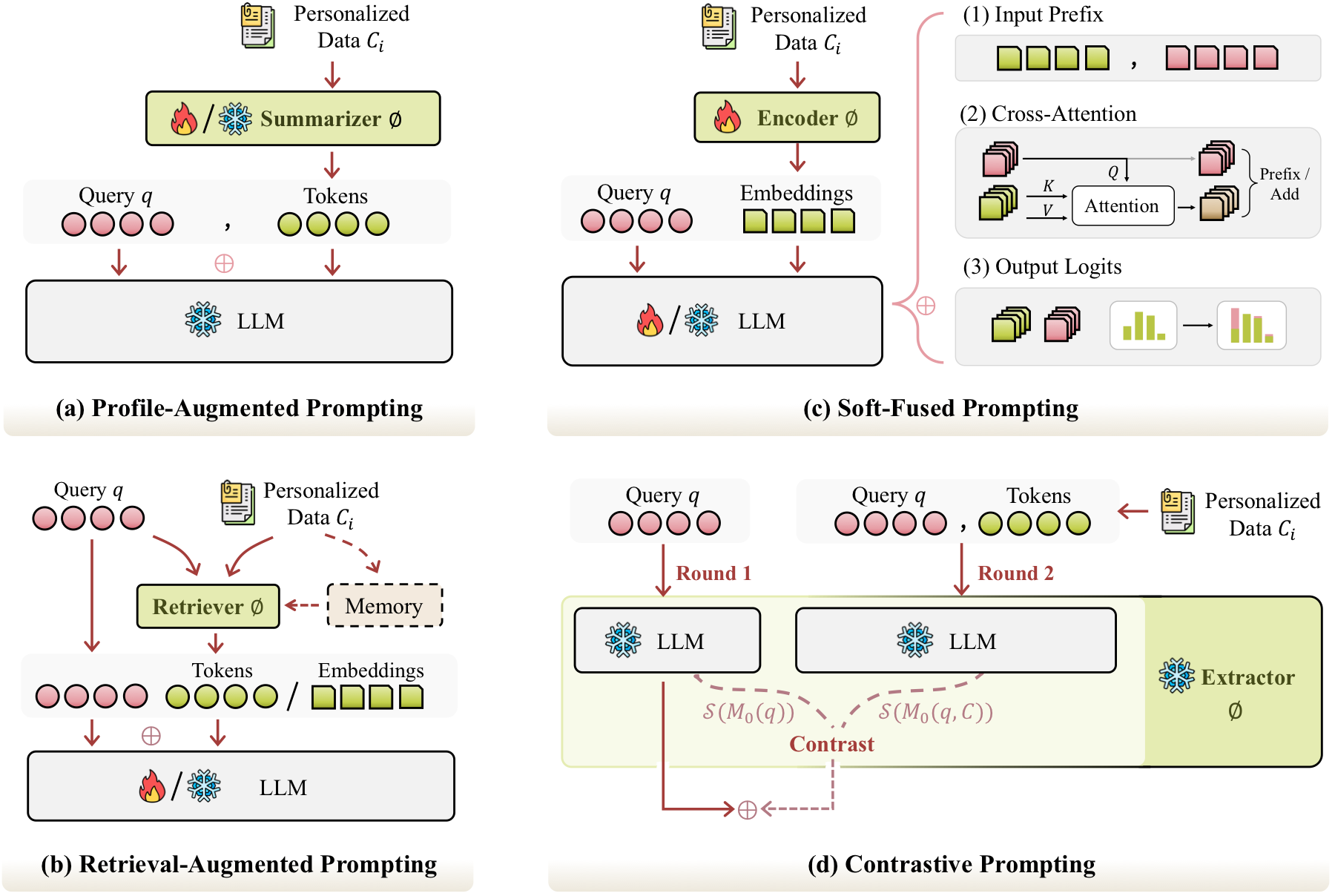
| Method Family | How It Works | Strength | Main Risk |
|---|---|---|---|
| Profile-Augmented | Summarize user history into profile tokens. | Efficient and easy to cache. | Compression may lose useful details. |
| Retrieval-Augmented | Retrieve relevant memories and concatenate them with the query. | Good fit for long-term memory and explicit facts. | Retrieval can be noisy or expensive. |
| Soft-Fused | Encode user data into embeddings, prefixes, attention signals, or logits. | Captures semantic nuance beyond text summaries. | Less interpretable and often harder for black-box deployment. |
| Contrastive | Compare model states with and without personal context. | More controllable and interpretable. | Sensitive to steering scale and hyperparameters. |
Path 2
Personalized Adaptation: deeper personalization with parameter trade-offs
Adaptation-based methods modify a small set of parameters or modules, often through PEFT. This makes them more capable than pure prompting when the target behavior is implicit, stylistic, or hard to express as retrieved text. The core design choice is whether all users share one personalized module or each user owns a separate module.
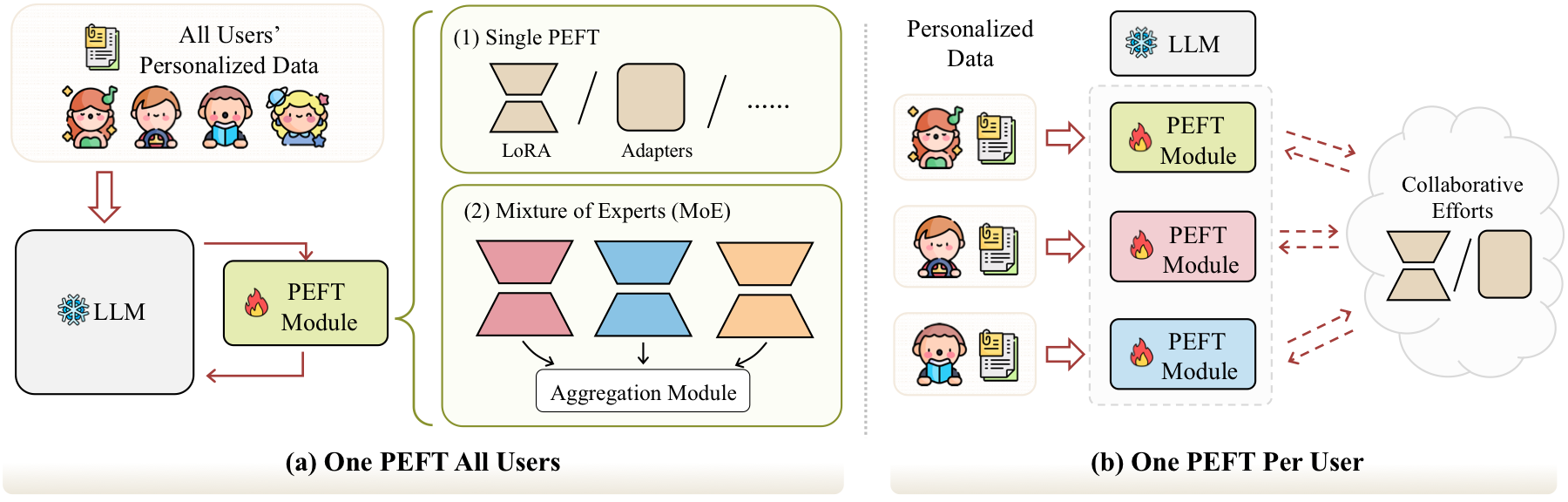
| Adaptation Strategy | Best For | Pros | Cons |
|---|---|---|---|
| One PEFT for All Users | Large-scale services with many users and limited adapter budget. | Parameter-efficient, scalable, easier to maintain. | May blur individual differences and depend heavily on user data encoding. |
| One PEFT Per User | High-stakes or private settings where user isolation matters. | Stronger personalization, better separation between users. | Higher storage, training, synchronization, and cold-start cost. |
| Collaborative or Federated PEFT | Settings that need both personalization and cross-user transfer. | Can share useful population-level signals without raw data sharing. | Must balance privacy leakage, communication cost, and robustness. |
Path 3
Personalized Alignment: preferences are not universal
Generic alignment optimizes for broad human preferences. Personalized alignment asks a different question: what if users disagree about style, values, depth, risk tolerance, or decision behavior? The survey treats this as a preference modeling problem, often connected to multi-objective reward learning, decoding-time model combination, and test-time feedback.
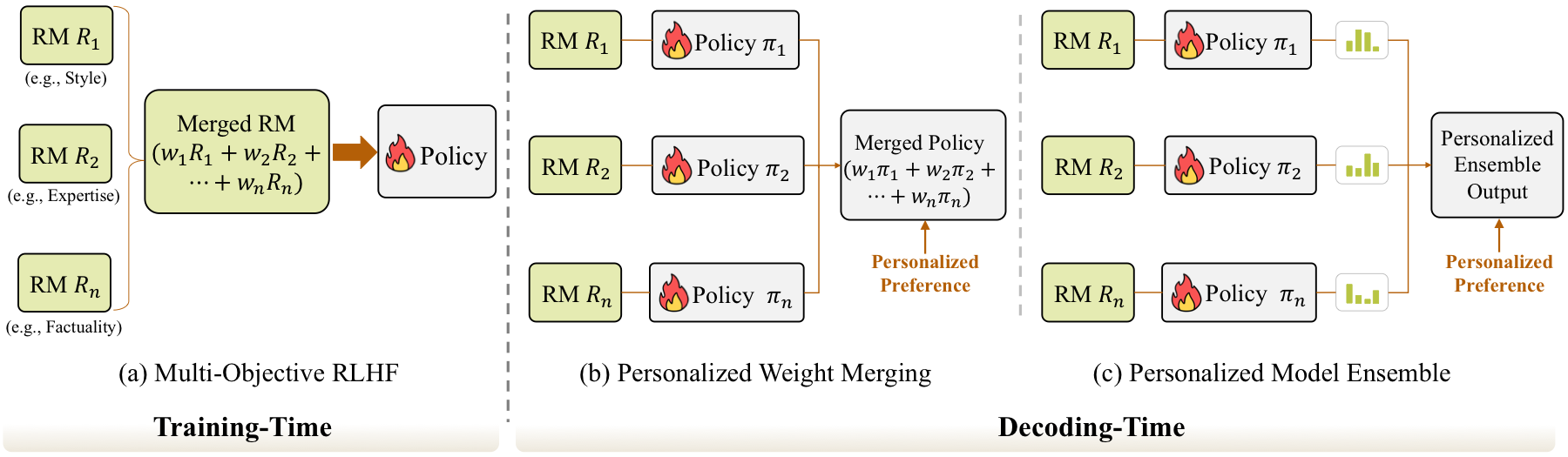
| Alignment Route | Personalization Mechanism | Strength | Limitation |
|---|---|---|---|
| Training-Time Personalization | Use user-specific reward mixtures during policy optimization. | Strong personalization and efficient inference. | High training cost and less flexibility after training. |
| Decoding-Time Personalization | Merge or ensemble policies using user-specific weights at inference. | Flexible and can adapt without retraining the base model. | Extra storage and inference overhead. |
| Test-Time Feedback | Update prompts, personas, or reward signals from live interactions. | Promising for evolving user preferences. | Benchmarks and stability guarantees remain underdeveloped. |
Evaluation
Personalization should be evaluated by data type, query type, and task
The benchmark landscape is broad because personalization itself is broad. Dialogue-based benchmarks often test memory extraction from conversation histories. Content-based benchmarks such as LaMP and LongLaMP test whether the model can incorporate a user's historical text. Preference-based benchmarks emphasize subjective alignment. Interaction-based benchmarks connect personalization to recommendation and user behavior modeling.
| Benchmark Group | Personalized Data | Typical Query | Common Metrics |
|---|---|---|---|
| MemoryBank, PerLTQA, LoCoMo, LongMemEval, MMRC, IMPLEXCONV, MemBench | User profiles and dialogues | Mostly extraction, with some abstraction and generalization | LLM-E, F1, Recall, Human-E, Acc |
| LaMP, LongLaMP, PEFT-U, pGraphRAG, LaMP-QA, DPL, PERSONABench | Historical content | Abstraction and generalization | Acc, F1, MAE, RMSE, ROUGE, BLEU, METEOR, LLM-E |
| PRISM, PersonalLLM, ALOE, HiCUPID | Human preferences and personas | Preference-aware generation | BLEU, ROUGE-L, LLM-E, human evaluation |
| REGEN, PersonalWAB, RecBench+ | User interactions and profiles | Recommendation or behavior-grounded generation | Acc, Precision, Recall, ROUGE-L, BLEU, SBERT |
Future directions
The next frontier is memory that can remember, adapt, and evolve
The survey's forward-looking view is that PLLMs should not only retrieve user-specific facts, but also abstract from long-term evidence and evolve as users change. This creates a difficult trilemma: stronger personalization tends to need more computation or more private data; stronger privacy often limits cross-user transfer; and scalable deployment on edge devices makes both constraints sharper.
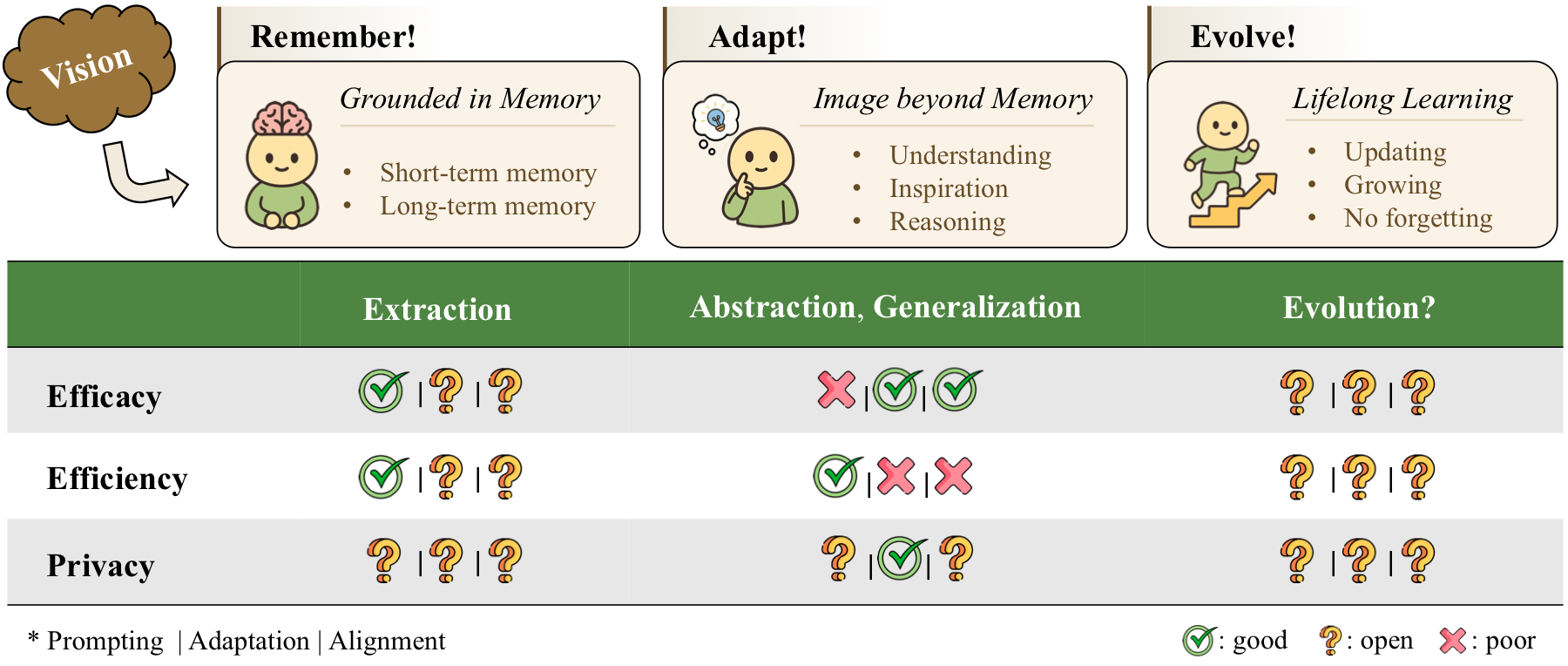
Complex User Data
Move beyond text-only histories toward multi-source, graph-like, and multimodal user signals.
Edge Computing
Support lightweight personalization on phones and local devices through small models, quantization, and distillation.
Edge-Cloud Collaboration
Balance local privacy with cloud-scale capability while reducing synchronization cost.
Model Updates
Update user-specific modules when base LLMs change without retraining everything from scratch.
Lifelong Updating
Let personal memories change over time without catastrophic forgetting or stale preferences.
Takeaways
A practical reading map
Use prompting when personalization mainly means retrieving explicit facts or adding lightweight context.
Use adaptation when the model must internalize implicit style, preferences, and behavior patterns.
Use alignment when the key problem is subjective preference, value trade-offs, or dynamic feedback.
Evaluate carefully because success depends on data type, query type, task type, and whether the metric actually measures personalization rather than generic generation quality.
Citation
@article{liu2025survey,
title={A Survey of Personalized Large Language Models: Progress and Future Directions},
author={Liu, Jiahong and Qiu, Zexuan and Li, Zhongyang and Dai, Quanyu and Yu, Wenhao and Zhu, Jieming and Hu, Minda and Yang, Menglin and Chua, Tat-Seng and King, Irwin},
journal={arXiv preprint arXiv:2502.11528},
year={2025}
}