PerFit: Exploring Personalization Shifts in Representation Space of LLMs
—— A two-stage representation-space fine-tuning method for efficient LLM personalization.
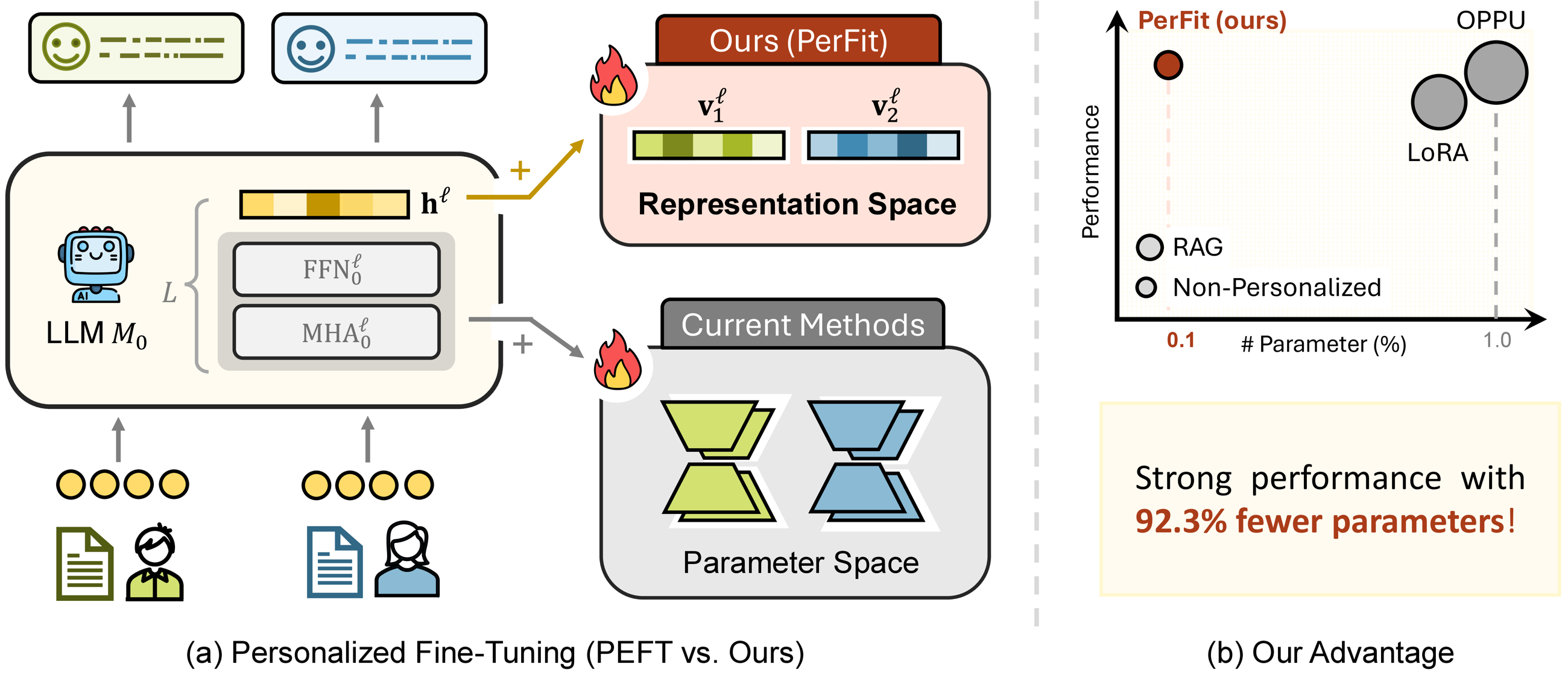
Highlights
Core Idea
Identify personalization shift and fine-tune personalized LLMs directly in representation space.
Key Result
Strong overall performance across all six LaMP personalization tasks.
Efficiency
81.25%-98.44% fewer trainable parameters and 17.0%-35.8% less training time.
Abstract
Personalization has become a pivotal field of study in contemporary intelligent systems. While large language models (LLMs) excel at general knowledge tasks, they often struggle with personalization, i.e., adapting their outputs to individual user expectations. Existing methods (e.g., RAG/PAG and LoRA-based PEFT) face challenges in balancing effectiveness and efficiency. PerFit first uncovers key patterns in representation space: personalized information lies in a low-rank subspace, and user vectors exhibit both a collective shift and user-specific shifts. Based on these findings, PerFit introduces a two-stage representation-space intervention tuning strategy that directly steers hidden representations with minimal parameter overhead.
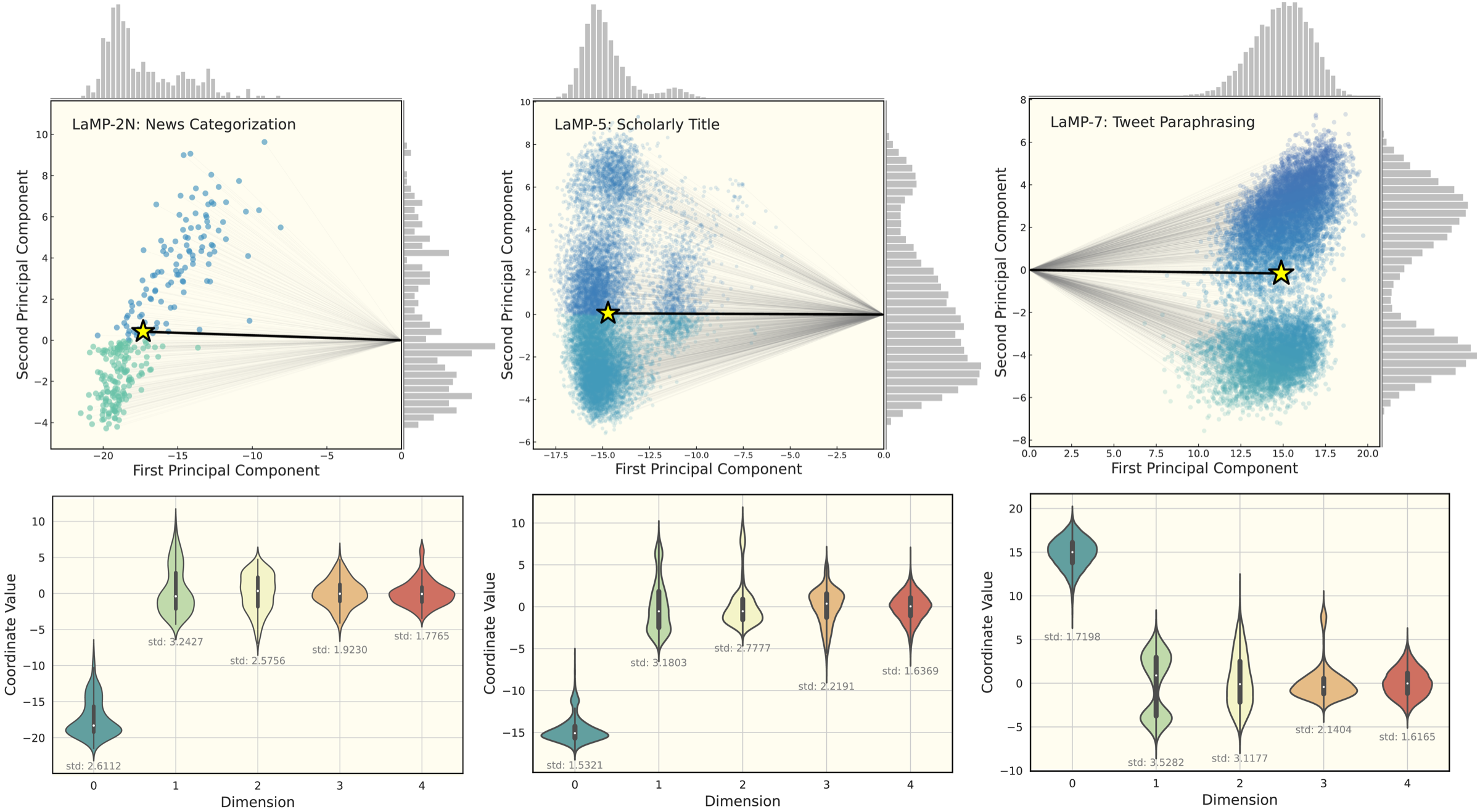
Key Observations
Delta vectors are extracted at each layer by taking the hidden-state difference
between original queries and personalization-enhanced queries for each user.
These delta vectors are then analyzed across users.
Observation 1: Low-rank Subspace
The delta vectors can be effectively represented within a low-dimensional orthogonal
subspace, significantly reducing the original feature space dimensionality.
| Dataset | r (0.8) | ‰ (0.8) | r (0.9) | ‰ (0.9) | r (0.95) | ‰ (0.95) |
|---|---|---|---|---|---|---|
| LaMP-2M | 1 | 1.21 | 3 | 3.62 | 12 | 14.48 |
| LaMP-2N | 1 | 3.65 | 4 | 14.60 | 20 | 72.90 |
| LaMP-3 | 3 | 0.73 | 18 | 4.39 | 93 | 22.71 |
| LaMP-4 | 34 | 22.03 | 167 | 108.23 | 368 | 238.50 |
| LaMP-5 | 4 | 0.98 | 40 | 9.77 | 203 | 49.56 |
| LaMP-7 | 3 | 0.73 | 32 | 7.81 | 177 | 43.21 |
Table 1 (+ appendix, same Llama backbone). Effective rank is far below full dimensionality, indicating strong low-rank structure.
Observation 2: Collective and Personalized Shifts
The delta vectors exhibit a collective shift, accompanied by personalized shifts
reflecting individual variability.
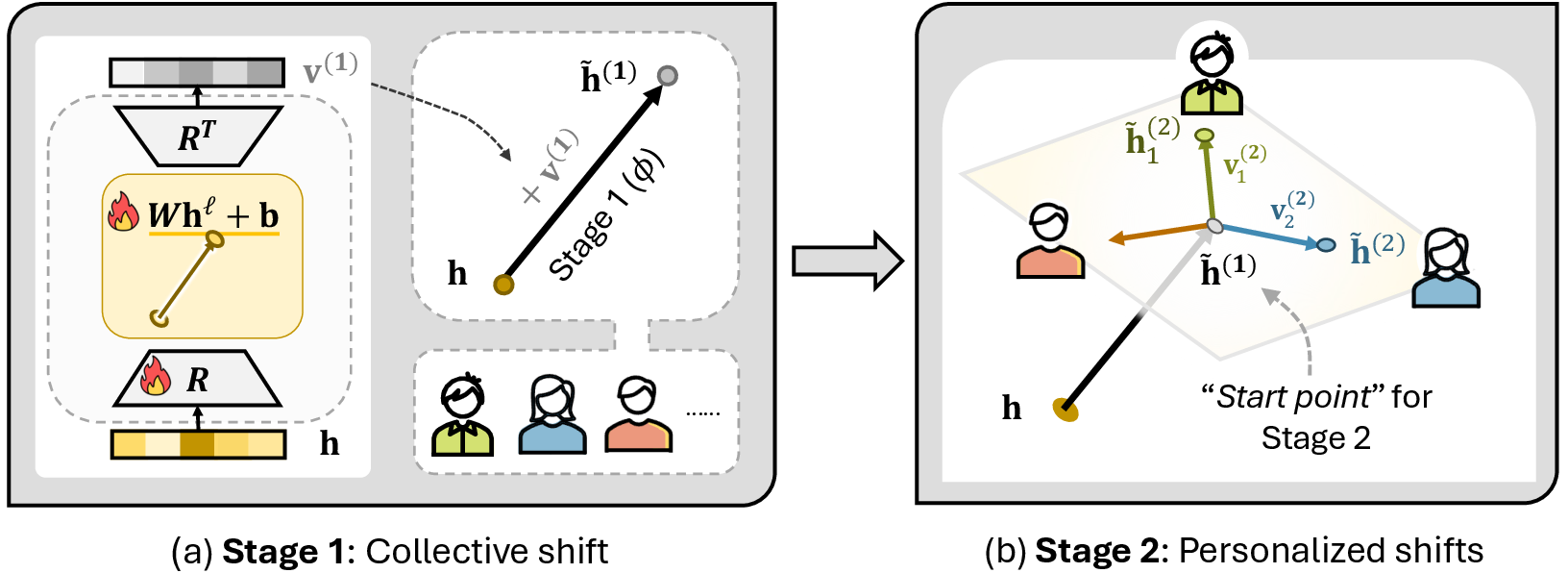
Method Overview
Stage-1 Collective Shift
Train on all users to learn a shared intervention in low-rank representation subspace.
Stage-2 Personalized Shift
Fine-tune user-specific interventions on top of Stage-1 for individual adaptation.
Main Results on LaMP
| Classification | LaMP-2N (Acc / F1) | LaMP-2M (Acc / F1) | LaMP-3 (MAE / RMSE) |
|---|---|---|---|
| OPPU | 0.810 / 0.589 | 0.600 / 0.493 | 0.179 / 0.443 |
| PerFit | 0.818 / 0.586 | 0.630 / 0.518 | 0.179 / 0.443 |
| Param. reduction vs OPPU | 93.75% / 81.25% | 91.67% / 98.44% | 87.50% / 97.66% |
| Generation | LaMP-4 (R-1 / R-L) | LaMP-5 (R-1 / R-L) | LaMP-7 (R-1 / R-L) |
|---|---|---|---|
| OPPU | 0.191 / 0.171 | 0.519 / 0.442 | 0.539 / 0.483 |
| PerFit | 0.207 / 0.186 | 0.521 / 0.451 | 0.525 / 0.472 |
| Param. reduction vs OPPU | 87.50% / 97.66% | 95.83% / 98.44% | 91.67% / 93.75% |
Citation
@inproceedings{liu2026perfit,
title={PerFit: Exploring Personalization Shifts in Representation Space of LLMs},
author={Liu, Jiahong and Yu, Wenhao and Dai, Quanyu and Li, Zhongyang and Zhu, Jieming and Yang, Menglin and Chua, Tat-Seng and King, Irwin},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}